
한글 타이핑 애니메이션을 구현하고 싶었습니다. 타이머 함수를 이용하면 구현 자체는 쉬웠지만, 단순히 한 글자씩 출력하는 것은 다소 밋밋했고, 실제로 타자를 치는 듯한 애니메이션을 만들어보고 싶었습니다.
구현 과정
한글 타이핑 애니메이션을 자연스럽게 구현하려면 입력받은 문자가 초성 → 초성+중성 → 초성+중성+종성 순으로 출력되어야 합니다. 예를 들어 "곰"이라는 글자는 화면에 ㄱ → 고 → 곰 형태로 출력될 때 더 자연스럽습니다. 이를 위해서는 입력받은 "곰" 문자를 초성/중성/종성으로 분리하는 과정이 필요합니다.
한글 문자를 분리할 때 가장 많이 사용되는 방법 중 하나가 유니코드를 이용하는 방식인데, 이를 위해서는 유니코드에서 한글이 어떤 규칙으로 배치되어 있는지 먼저 알아야 합니다.
한글 유니코드의 규칙
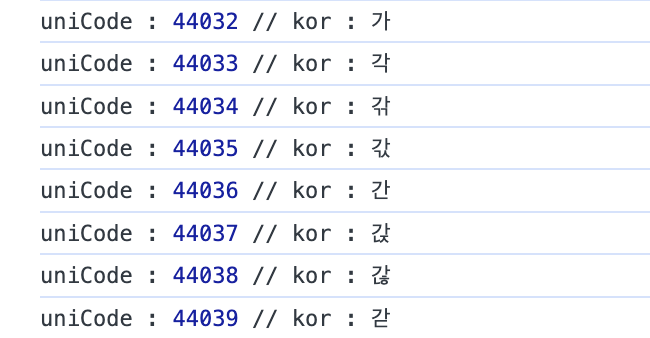
다음 함수는 '가'부터 '힣'까지 한글 유니코드를 출력하는 함수입니다.
export function showkoreanAllUnicode() {
// 문자를 유니코드로 변환
const ga = "가".charCodeAt(0); // 가 (맨 처음 한글 문자)
const hih = "힣".charCodeAt(0); // 힣 (맨 마지막 한글 문자)
let uni = ga;
while (uni) {
const kor = String.fromCharCode(uni); // 유니코드를 문자로 변환
console.log("uniCode :", uni, "// kor : " + kor);
if (uni === hih) break;
uni++;
}
}
showkoreanAllUnicode(); // '가' ~ '힣'까지 모든 한글 unicode 출력해당 함수를 호출해보면 콘솔에 아래처럼 출력됩니다. 살펴보면 종성은 1마다, 중성은 28마다, 초성은 588마다 변하는 것을 확인할 수 있습니다.
이 규칙을 이용하면 아래처럼 문자를 분리하는 함수를 만들 수 있습니다.
// 초성 배열
const f = ['ㄱ', 'ㄲ', 'ㄴ', 'ㄷ', 'ㄸ', 'ㄹ', 'ㅁ',
'ㅂ', 'ㅃ', 'ㅅ', 'ㅆ', 'ㅇ', 'ㅈ', 'ㅉ',
'ㅊ', 'ㅋ', 'ㅌ', 'ㅍ', 'ㅎ'];
// 중성 배열
const s = ['ㅏ', 'ㅐ', 'ㅑ', 'ㅒ', 'ㅓ', 'ㅔ', 'ㅕ',
'ㅖ', 'ㅗ', 'ㅘ', 'ㅙ', 'ㅚ', 'ㅛ', 'ㅜ',
'ㅝ', 'ㅞ', 'ㅟ', 'ㅠ', 'ㅡ', 'ㅢ', 'ㅣ'];
// 종성 배열(공백 포함)
const t = ['', 'ㄱ', 'ㄲ', 'ㄳ', 'ㄴ', 'ㄵ', 'ㄶ',
'ㄷ', 'ㄹ', 'ㄺ', 'ㄻ', 'ㄼ', 'ㄽ', 'ㄾ',
'ㄿ', 'ㅀ', 'ㅁ', 'ㅂ', 'ㅄ', 'ㅅ', 'ㅆ',
'ㅇ', 'ㅈ', 'ㅊ', 'ㅋ', 'ㅌ', 'ㅍ', 'ㅎ'];
// 문자를 분해하여 초성, 중성, 종성 순으로 출력하는 함수
function disassembleKoreanChar(char: string): string[] {
const ga = "가".charCodeAt(0); // 가 (맨 처음 한글 문자)
const giyeok = "ㄱ".charCodeAt(0); // 'ㄱ' (맨 처음 한글 자음)
const uniCode = char.charCodeAt(0) - ga; // 입력받은 문자의 유니코드와 '가' 유니코드의 차
// 한글이 아닐 경우 예외처리
if (uniCode < 0 || uniCode > hih - giyeok) {
return [char, "", ""];
}
// 종성은 1마다, 중성은 28마다, 초성은 588마다 값이 변함
// 초성 배열의 인덱스
const fIdx = Math.floor(uniCode / 588);
// 중성 배열의 인덱스
const sIdx = Math.floor((uniCode - fIdx * 588) / 28);
// 종성 배열의 인덱스
const tIdx = Math.floor(uniCode % 28);
return [f[fIdx], s[sIdx], t[tIdx]];
}
const result = disassembleKoreanChar('곰');
console.log(result); // ['ㄱ', 'ㅗ', 'ㅁ']우선 uniCode 변수에 입력받은 문자의 유니코드 값에서 '가'의 유니코드를 뺀 값을 저장합니다. 이 값을 기반으로 초성/중성/종성 값을 구합니다.
fIdx는 초성 배열의 인덱스입니다. 초성은 588마다 값이 바뀌고 배열의 시작 인덱스는 0이므로 uniCode를 588로 나눈 뒤 Math.floor()로 내림 처리합니다.
sIdx는 중성 배열의 인덱스입니다. 중성은 28마다 값이 바뀌므로 28로 나누며, 초성이 바뀔 때마다 중성이 다시 처음부터 반복되기 때문에 uniCode에서 fIdx * 588을 빼서 보정한 뒤 계산합니다.
tIdx는 종성 배열의 인덱스입니다. 종성은 1마다 값이 바뀌고 총 28개의 값을 가지므로 uniCode % 28이 종성 배열의 인덱스가 됩니다.
위 코드를 응용하면 아래처럼 [초성, 초성+중성, 초성+중성+종성] 순으로 출력하는 함수를 만들 수 있습니다.
// 초성 배열
const f = ['ㄱ', 'ㄲ', 'ㄴ', 'ㄷ', 'ㄸ', 'ㄹ', 'ㅁ',
'ㅂ', 'ㅃ', 'ㅅ', 'ㅆ', 'ㅇ', 'ㅈ', 'ㅉ',
'ㅊ', 'ㅋ', 'ㅌ', 'ㅍ', 'ㅎ'];
// 중성 배열
const s = ['ㅏ', 'ㅐ', 'ㅑ', 'ㅒ', 'ㅓ', 'ㅔ', 'ㅕ',
'ㅖ', 'ㅗ', 'ㅘ', 'ㅙ', 'ㅚ', 'ㅛ', 'ㅜ',
'ㅝ', 'ㅞ', 'ㅟ', 'ㅠ', 'ㅡ', 'ㅢ', 'ㅣ'];
// 종성 배열(공백 포함)
const t = ['', 'ㄱ', 'ㄲ', 'ㄳ', 'ㄴ', 'ㄵ', 'ㄶ',
'ㄷ', 'ㄹ', 'ㄺ', 'ㄻ', 'ㄼ', 'ㄽ', 'ㄾ',
'ㄿ', 'ㅀ', 'ㅁ', 'ㅂ', 'ㅄ', 'ㅅ', 'ㅆ',
'ㅇ', 'ㅈ', 'ㅊ', 'ㅋ', 'ㅌ', 'ㅍ', 'ㅎ'];
export function disassembleKoreanString(char: string): string[] {
const ga = "가".charCodeAt(0); // 가 (맨 처음 한글 문자)
const giyeok = "ㄱ".charCodeAt(0); // 'ㄱ' (맨 처음 한글 자음)
const uniCode = char.charCodeAt(0) - ga;
// 한글이 아닐 경우 예외처리
if (uniCode < 0 || uniCode > hih - giyeok) {
return [char, "", ""];
}
// 종성은 1마다, 중성은 28마다, 초성은 588마다 값이 변함
// 초성 인덱스
const fIdx = Math.floor(uniCode / 588);
// 중성 인덱스
const sIdx = Math.floor((uniCode - fIdx * 588) / 28);
// 종성 인덱스
const tIdx = Math.floor(uniCode % 28);
// [초성, 초성 + 중성, 초성 + 중성 + 종성] 배열을 출력
return [
f[fIdx],
String.fromCharCode(ga + fIdx * 588 + sIdx * 28),
t[tIdx] ? String.fromCharCode(ga + fIdx * 588 + sIdx * 28 + tIdx) : "",
];
}
const result = disassembleKoreanString('곰');
console.log(result); // ['ㄱ','고','곰']위 함수 안에 사용된 String.fromCharCode는 유니코드 값에 해당하는 문자를 출력하는 함수입니다.
여기에 인자로 '가'의 유니코드 + (초성 인덱스 x 초성 간의 간격) + (중성의 인덱스 x 중성 간의 간격) + 종성 인덱스를 넣으면 초성 + 중성 + 종성을 다 더한 문자를 구할 수 있습니다. 이를 응용해서 마지막에 종성 인덱스를 생략하면 초성 + 중성을 더한 문자 또한 구할 수 있습니다.
따라서 위 함수는 문자를 입력받으면 해당 문자의 [초성, 초성+중성, 초성+중성+종성] 순으로 이루어진 배열을 출력합니다. 예를 들어 함수에 "곰"이라고 입력하면 ["ㄱ", "고", "곰"] 형태로 출력됩니다. 또한 함수 외부에서 사용하기 쉽도록, 입력받은 글자가 한글이 아니더라도 배열 길이를 3으로 맞춰 반환하도록 만들었습니다.
하지만 위 함수는 단일 문자만 처리할 수 있으므로, 문자열을 입력받았을 때도 처리할 수 있도록 별도의 함수를 하나 더 만들었습니다.
// 입력받은 문자열을 쪼갠 결과값을 출력하는 함수
function disassembleString(line: string): string[] {
let titleArr: { a: string; b: string; c: string }[] = [];
[...line].forEach((char) => {
titleArr = titleArr.concat(disassembleKoreanString(char));
});
return titleArr;
}
const result = disassembleString('곰돌이');
console.log(result); // ['ㄱ', '고', '곰', 'ㄷ', '도', '돌', 'ㅇ', '이', '']disassembleString 함수는 입력받은 문자열의 길이만큼 disassembleKoreanString 함수를 호출하고, 그 결과 배열들을 하나로 합쳐 반환하는 함수입니다.
예를 들어 "곰돌이"라고 입력한 경우 disassembleKoreanString 함수를 3번 호출해야 하는데 각각 ['ㄱ', '고', '곰'], ['ㄷ', '도', '돌'], ['ㅇ', '이', ''] 3개의 배열이 출력됩니다. 반면 disassembleString 함수를 사용하면 ['ㄱ', '고', '곰', 'ㄷ', '도', '돌', 'ㅇ', '이', '']처럼 하나의 배열로 받을 수 있습니다.
최종적으로 disassembleString 함수로 출력된 배열을 화면에 출력하는 작업도 필요합니다. 이때 한글이 아닌 문자가 입력되거나 종성이 없는 문자가 입력되었을 경우도 고려해 예외 처리를 해주는 것이 중요합니다.
let timerId = 0;
// 문자 배열을 입력받아 화면에 출력하는 함수
function typing(element: Element, txt: string) {
return new Promise((resolve) => {
let idx = 0;
timerId = setInterval(function () {
if (idx % 3 === 0) {
// 다음 글자로 넘어갈 때 글자 추가
element.innerHTML += txt[idx];
} else {
// 현재 글자일 때 초성, 초성 + 중성, 초성 + 중성 + 종성 순으로 출력
if (txt[idx] !== "") {
// 중성/종성이 공백일 때 무시
element.innerHTML = element.innerHTML.slice(0, -1) + txt[idx];
}
}
idx++;
if (txt.length <= idx) {
clearInterval(timerId);
idx = 0;
resolve(true);
}
}, 100);
});
}
typing(titleElement, disassembleString('곰돌이')); // 화면에 곰돌이 출력typing 함수는 100ms마다 disassembleString을 통해 만들어진 문자 배열의 요소들을 화면에 출력하는 함수입니다. 반복문을 한 번 돌 때마다 idx 값이 1씩 증가하며, idx 값이 3의 배수가 아닌 경우 현재까지 출력된 문자열의 마지막 문자를 현재 idx의 문자로 치환하고, idx 값이 3의 배수인 경우에는 출력된 문자열 끝에 새 문자를 추가합니다.
3을 기준으로 정한 이유는 disassembleString에서 반환되는 문자 배열의 길이가 항상 3의 배수이기 때문입니다. 실제로 함수 내부에서 console.log를 찍어보면 문자 배열 길이가 9인 것을 확인할 수 있습니다.

또한 Promise를 사용해 typing 함수를 여러 번 호출하더라도 순서대로 한 줄씩 화면에 출력되도록 구성했습니다.
출력 결과
typing 함수를 실행한 결과는 다음과 같습니다. 사진처럼 자음/모음이 잘 분리되어 출력되며, 한글이 아닌 다른 문자를 넣어도 자연스럽게 출력되는 것을 확인할 수 있습니다.

쌍자음과 복합 종성 테스트
쌍자음이나 복합 종성이 포함된 문자에서도 정상 동작하는지 확인한 결과입니다.
| 입력 | 분해 결과 | 타이핑 시퀀스 | 정상 여부 |
|---|---|---|---|
| 곰 | ㄱ, ㅗ, ㅁ | ㄱ → 고 → 곰 | O |
| 쏟 | ㅆ, ㅗ, ㄷ | ㅆ → 쏘 → 쏟 | O |
| 닭 | ㄷ, ㅏ, ㄺ | ㄷ → 다 → 닭 | O |
| 없 | ㅇ, ㅓ, ㅄ | ㅇ → 어 → 없 | O |
| 읽 | ㅇ, ㅣ, ㄺ | ㅇ → 이 → 읽 | O |
| 뷁 | ㅂ, ㅞ, ㄺ | ㅂ → 붸 → 뷁 | O |
쌍자음과 복합 종성 모두 배열에 포함되어 있어 분해 자체는 문제없이 동작합니다. 다만 복합 종성은 하나의 단위로 처리되므로, "닭"은 ㄷ → 다 → 닭으로 출력됩니다. 실제 키보드처럼 ㄷ → 다 → 달 → 닭으로 보여주려면 복합 종성을 개별 자음으로 추가 분해하는 로직이 필요합니다.
// 복합 종성 분해 매핑
const complexFinal = {
'ㄳ': ['ㄱ', 'ㅅ'], 'ㄵ': ['ㄴ', 'ㅈ'], 'ㄶ': ['ㄴ', 'ㅎ'],
'ㄺ': ['ㄹ', 'ㄱ'], 'ㄻ': ['ㄹ', 'ㅁ'], 'ㄼ': ['ㄹ', 'ㅂ'],
'ㄽ': ['ㄹ', 'ㅅ'], 'ㄾ': ['ㄹ', 'ㅌ'], 'ㄿ': ['ㄹ', 'ㅍ'],
'ㅀ': ['ㄹ', 'ㅎ'], 'ㅄ': ['ㅂ', 'ㅅ'],
};이 매핑을 활용하면 "닭"을 ㄷ → 다 → 달 → 닭 4단계로 출력할 수 있어, 타이핑이 한층 자연스럽게 느껴집니다.
샘플 코드
참고 자료
Related Posts

Vanilla JS 댓글 모듈 자체 개발기
프레임워크 독립적인 Vanilla JS 댓글 모듈을 설계·개발하고 기존에 서비스 중이던 Nuxt 3 프로젝트에 통합한 과정을 다룹니다.

리다이렉트 이후 window.opener가 null이 되는 문제 해결
외부 도메인 리다이렉트 이후 팝업의 `window.opener`가 사라지는 이슈를 `window.name`과 `window.open(name)`으로 복구한 방법을 정리합니다.

화살표 함수의 특징과 일반 함수와의 차이점
화살표 함수(Arrow Function)의 문법과 this/arguments/constructor/prototype/yield 등 일반 함수와의 핵심 차이점을 예제와 함께 정리합니다.