
이 글은 "AI가 다 만들어줬다"는 이야기가 아닙니다. 제약이 많은 상황에서 AI를 활용해 쓸 만한 시스템을 빠르게 만든 경험이며, 그 과정에서 AI 생성 코드보다 설계와 검증이 더 중요하다는 점을 확인한 기록입니다.
만들게 된 배경
기존에 도입했던 외부 챗봇 서비스는 비용 부담이 있었고, 스크립트가 프론트 코드와 충돌하는 문제도 있었습니다. 교체를 검토하던 중 시연 일정이 잡혔고, 짧은 시간 안에 최소한으로 동작하는 챗봇이 필요했습니다.
문제는 백엔드 지원을 받기 어려운 상황이었다는 점입니다. 백엔드 팀은 별도 일정으로 바빴고, DB 설계나 API 서버 구축을 새로 시작할 여유가 없었습니다. 프론트엔드 중심으로 최대한 자급자족해야 했고, 그래서 택한 방향은 완벽한 구조보다 빠른 적용성이었습니다. AI를 적극적으로 활용하기로 한 것도 이 맥락에서였습니다.
구현 목표와 제약
시작할 때 제가 고려했던 점은 크게 세 가지였습니다.
- 어느 프론트 프로젝트에서도 붙일 수 있어야 함: 특정 프레임워크에 종속되지 않아야 했습니다. 기존 챗봇 스크립트를 사용하던 프로젝트들은 Nuxt, Next 등 프레임워크들이 각각 달랐기 때문입니다.
- CSS는 호스트 프로젝트에서 오버라이딩 가능해야 함: 각 서비스마다 디자인이 달랐기 때문에 기본적인 뼈대는 유지하되, 폰트, 컬러 토큰 등을 커스텀할 수 있는 유연성이 필요했습니다.
- 빠르게 시연 가능한 수준까지: 완성도보다 동작하는 것이 우선이었습니다.
전체 구조 설계
핵심: 코어와 UI를 분리하기
챗봇 구조는 크게 세 개의 패키지로 나눴습니다. LLM API 호출과 S3 접근 같은 로직은 호스트 프로젝트(Nuxt, Next 등)의 server-side에서 import해 바로 쓸 수 있도록 공통 패키지(core)로 분리했고, UI는 어느 프로젝트에서나 붙일 수 있는 위젯(widget)으로 따로 뒀습니다. 그리고 자체 서버가 없는 환경에서 로컬 테스트를 할 수 있도록 독립 실행형 서버(server)도 별도로 만들었습니다. 초안 코드는 AI가 빠르게 잡아줬지만, 패키지 경계와 책임 분리는 사람이 계속 조정해야 했습니다.
chatbot/
├── packages/
│ ├── core/ # LLM 서비스, S3 저장소, 지식 개선 로직
│ │ └── data/
│ │ ├── prompt/
│ │ │ └── com.txt # 테넌트별 시스템 프롬프트
│ │ ├── knowledge/
│ │ │ └── com.md # 챗봇이 참조하는 지식 문서
│ │ └── faq/
│ │ └── com.json # 초기 FAQ 선택지 데이터
│ ├── widget/ # 바닐라 JS 위젯 (npm 패키지로 배포)
│ └── server/ # 독립형 Express 서버 (로컬 개발용)
core에는 LLM API 연동, S3 로깅, 자동 지식 보강 등 비즈니스 로직이 담겨 있습니다. widget은 프레임워크 무관하게 어디서나 <script> 태그 하나로 붙일 수 있는 UI 패키지입니다. server는 독립 실행 가능한 Express 서버로, Next.js처럼 자체 서버가 있는 프레임워크에서는 해당 프레임워크의 API Route를 직접 사용하면 됩니다.
data/ 하위의 세 파일이 챗봇의 답변 품질을 결정하는 핵심입니다.
prompt/com.txt: LLM에 넘기는 시스템 프롬프트. "당신은 {서비스명} 고객 지원 챗봇입니다. 다음 지식 문서를 참고해 답변하세요"처럼 역할과 제약을 정의합니다.knowledge/com.md: 실제 서비스 FAQ를 Q&A 형식으로 정리한 마크다운 문서. 시스템 프롬프트와 함께 LLM 컨텍스트로 주입됩니다. 이 파일이 풍부할수록 답변 정확도가 높아지고, 빈약하면 LLM이 추측으로 답변합니다.faq/com.json: 위젯 최초 진입 시 보여주는 카테고리형 선택지 데이터. "구매/환불", "회원/계정" 같은 카테고리로 구분해 사용자가 자주 묻는 주제를 바로 선택할 수 있도록 안내합니다.
com, nom은 테넌트 ID, 쉽게 말해 어떤 내부 서비스에서 사용할지 선택할 식별자입니다. 다른 서비스를 붙일 때는 파일명만 맞춰 추가하면 별도 코드 수정 없이 분리됩니다.
멀티 테넌트 지원
내부에 서비스가 여러 개 있었고, 챗봇을 붙일 때마다 별도 레포를 만들거나 코드를 복사하는 방식은 피하고 싶었습니다. 그래서 테넌트 ID 하나만 바꾸면 완전히 다른 서비스처럼 동작하도록 설계했습니다.
tenantId = "com" tenantId = "nom"
───────────────────────────────── ─────────────────────────────────
data/prompt/com.txt data/prompt/nom.txt
data/knowledge/com.md data/knowledge/nom.md
data/faq/com.json data/faq/nom.json
S3 prefix: chat-logs/ S3 prefix: nom-chat-logs/
위젯 초기화 시 tenantId를 넘기면 이후 모든 요청 헤더에 자동으로 포함되고, 서버에서는 이 값으로 프롬프트·지식 문서·S3 경로를 분기합니다.
ChatBot.init({
serverUrl: "/api",
tenantId: "com", // 모든 요청에 X-Tenant-Id 헤더로 전달
userId: currentUser.id,
});새 서비스를 붙일 때 해야 하는 일은 데이터 파일(prompt, knowledge, faq) 추가와 초기화 시 tenantId 지정뿐입니다. 서버 코드나 핸들러는 건드리지 않아도 됩니다.
npm 패키지 형태로 만든 이유
내부 여러 프로젝트에서 재사용하기 위해 npm 패키지 두 개로 배포했습니다. 호스트 프로젝트에서는 API Route 몇 개만 추가하면 바로 붙일 수 있도록 설계했습니다.
@{scope}/chatbot-core — LLM, S3, 핸들러 로직 (내부 npm 패키지)
@{scope}/chatbot — 바닐라 JS 위젯 UI (내부 npm 패키지)
프레임워크별 연동 방식 비교
설계 과정에서 가장 많이 고민한 부분이 "어떤 프론트 프로젝트에 붙이더라도 별도 서버를 띄우지 않아도 되게 하려면 어떻게 해야 하는가"였습니다. React SPA처럼 정적 배포 환경이라면 별도 서버가 필요하지만, Next.js나 Nuxt처럼 자체 서버가 있는 프레임워크라면 그 안에서 처리할 수 있습니다.
이를 위해 핸들러를 모두 Web Standard Request / Response 기반으로 작성했습니다. 특정 프레임워크 타입에 의존하지 않기 때문에 어느 환경에서든 같은 코드를 그대로 쓸 수 있습니다.
Next.js App Router (API Route)
// app/api/chat/stream/route.ts
import { chatStreamHandler } from "@{scope}/chatbot-core";
import { sessionService, llmService } from "@/lib/chatbot";
export async function POST(req: Request) {
return chatStreamHandler(req, { sessionService, llmService });
}
// app/api/faq/route.ts
import { faqHandler } from "@{scope}/chatbot-core";
export async function GET(req: Request) {
return faqHandler(req, { defaultTenantId: "com" });
}
// app/api/sessions/[id]/route.ts
import { sessionHandler } from "@{scope}/chatbot-core";
const handler = sessionHandler({ sessionService });
export const GET = (_req: Request, { params }: { params: { id: string } }) =>
handler.GET(_req, params.id);
export const DELETE = (_req: Request, { params }: { params: { id: string } }) =>
handler.DELETE(_req, params.id);독립형 Express 서버 (React SPA 등)
자체 서버가 없는 환경이라면 packages/server의 Express 앱을 별도로 배포합니다. 핸들러 로직은 동일하고 Express 어댑터만 추가된 구조입니다.
// packages/server/src/app.ts
app.use("/", createRouter(sessionService, llmService, loadSystemPrompt));두 방식의 차이를 정리하면 다음과 같습니다.
| 항목 | Next.js / Nuxt (API Route) | 독립 Express 서버 |
|---|---|---|
| 별도 서버 필요 여부 | 불필요 | 필요 |
| 배포 복잡도 | 낮음 (기존 배포 파이프라인 활용) | 높음 (ECS 등 별도 인프라) |
| 핸들러 코드 | 동일 (@{scope}/chatbot-core) | 동일 (@{scope}/chatbot-core) |
| 적합한 환경 | Next.js, Nuxt 등 SSR 프레임워크 | React SPA, 정적 배포 환경 |
핵심은 핸들러 로직이 한 곳에만 존재한다는 점입니다. Express든 Next.js Route Handler든 chatStreamHandler를 그대로 호출하면 되기 때문에 연동 방식에 따라 비즈니스 로직이 달라지는 일이 없습니다.
실제 동작 흐름
구조 설명이 길어졌으니, 실제로 사용자가 위젯을 열었을 때 어떤 순서로 동작하는지 정리합니다. 흐름은 크게 두 갈래입니다.
흐름 1: 위젯 오픈 → FAQ 카테고리 표시
[사용자: 위젯 버튼 클릭]
│
▼
[widget: ChatBotInstance.open()]
GET /api/faq?tenant=com
│
▼
[faqHandler]
data/faq/com.json 로드 (캐시)
→ [{ category: "구매/환불", items: [...] }, ...]
│
▼
[widget: faqSectionTemplate 렌더링]
카테고리 칩 표시 → 선택 시 질문 목록 표시
질문 선택 시 → faqAnswerTemplate으로 즉시 답변 표시
(LLM 호출 없음)
FAQ 항목을 선택하면 LLM API를 거치지 않고 FAQ 데이터 파일(data/faq/com.json)에 저장된 답변을 그대로 보여줍니다. 응답 속도가 빠르고, 자주 묻는 질문은 환각 없이 정확한 내용을 보장할 수 있습니다.
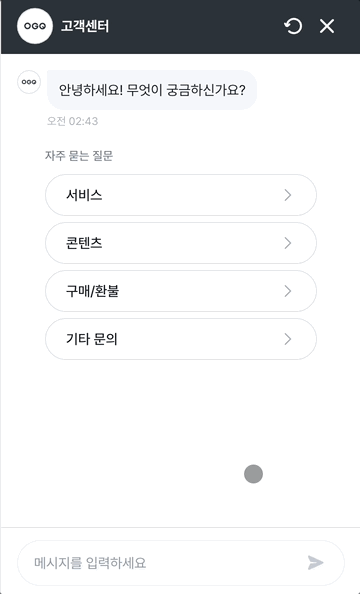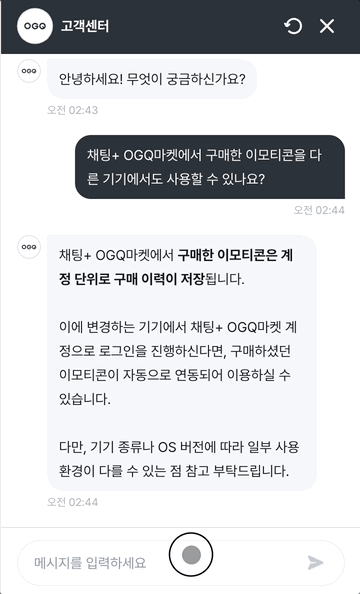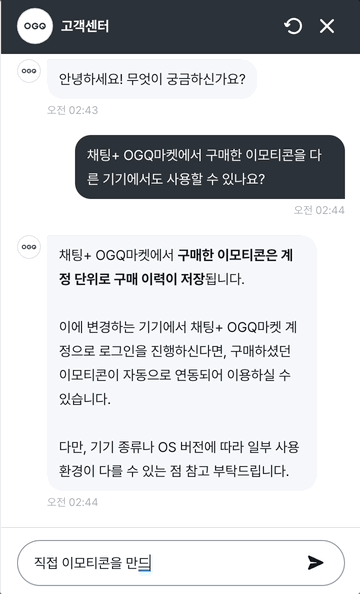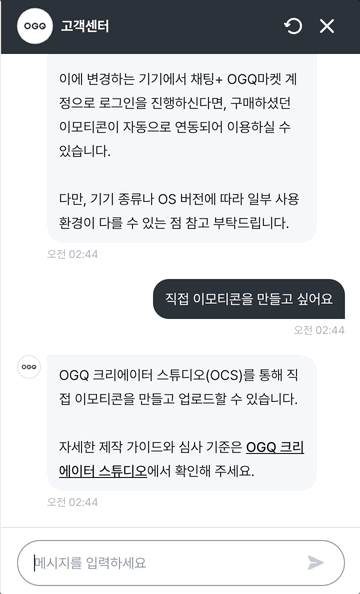
흐름 2: 사용자 직접 입력 → LLM 스트리밍 응답
[사용자: 메시지 직접 입력]
│
▼
[widget: HttpChatAPI.sendMessageStream()]
POST /api/chat/stream
Headers: X-Tenant-Id, X-User-Id, ...
Body: { sessionId, message }
│
▼
[chatStreamHandler]
│
├─ sessionService.ensureSession()
│ └─ S3에서 세션 조회, 없으면 새로 생성
│
├─ sessionService.appendMessage() ← 사용자 메시지 S3 저장
│
├─ llmService.streamChat(history, message)
│ └─ system prompt + knowledge.md 컨텍스트 포함
│ LLM API → AsyncGenerator<chunk>
│
└─ ReadableStream으로 SSE 청크 전송
data: {"type":"start"}
data: {"type":"chunk","content":"안녕"}
data: {"type":"chunk","content":"하세요"}
data: {"type":"done","fullContent":"안녕하세요"}
data: [DONE]
└─ 완료 시 assistant 메시지 S3 저장
(토큰 수, 레이턴시 포함)
│
▼
[widget: reader.read() 루프]
onChunk → 글자 단위로 버블에 append
onDone → 최종 메시지 확정
│
▼
[화면에 실시간 렌더링]
위젯 쪽에서는 ReadableStream의 reader를 직접 읽으면서 data: 접두사로 시작하는 SSE 라인을 파싱합니다. 청크가 들어올 때마다 DOM을 업데이트하기 때문에 LLM이 글자를 생성하는 즉시 화면에 표시됩니다.
// HttpChatAPI.ts — SSE 청크 파싱
const reader = res.body.getReader();
const decoder = new TextDecoder();
let buffer = "";
while (true) {
const { done, value } = await reader.read();
if (done) break;
buffer += decoder.decode(value, { stream: true });
const lines = buffer.split("\n");
buffer = lines.pop() ?? "";
for (const line of lines) {
if (!line.startsWith("data: ")) continue;
const payload = line.slice(6).trim();
if (payload === "[DONE]") return;
const event = JSON.parse(payload);
if (event.type === "chunk") callbacks.onChunk(event.content);
if (event.type === "done") callbacks.onDone(event.fullContent, sessionId);
}
}스트림이 끝나면 토큰 수와 레이턴시를 포함한 done 이벤트가 마지막으로 내려옵니다. 이 메타데이터는 S3 세션에 함께 저장돼 나중에 비용 추적이나 성능 분석에 쓸 수 있습니다.
빠른 구현을 위한 설계 결정
DB 대신 S3를 선택한 이유
백엔드 지원을 받기 어려운 상황에서 DB 설계와 운영까지 감당하기는 어려웠고, 빠르게 저장 구조를 만들어야 했습니다. 대화 세션을 JSON 파일 한 개로 직렬화해서 S3에 저장하는 방식을 택했습니다.
// S3에 세션을 JSON으로 저장
private async putSession(session: Session): Promise<void> {
const key = this.sessionKey(session.conversationId);
await this.client.send(
new PutObjectCommand({
Bucket: this.bucket,
Key: key,
Body: JSON.stringify(session, null, 2),
ContentType: 'application/json',
}),
);
}세션 키 구조는 {prefix}/{conversationId}.json 형태입니다. 멀티 테넌트를 prefix로 구분합니다. 예: chat-logs/abc-123.json, nom-chat-logs/def-456.json.
- 별도 DB 인프라 없이 바로 구현 가능
- 테넌트별 prefix로 간단하게 격리
- JSON이라 세션 내용 확인이 쉬움
- 특정 기간의 대화량, 사용자별 통계 등 집계 쿼리 불가
- 전체 세션 스캔이 필요한 분석은 S3 ListObjects를 순회해야 함
- 동시 접속이 많을 경우 S3 API 비용과 레이턴시 이슈 가능
- React SPA처럼 서버리스 환경에서는 현재 구조로 사용 불가: S3에 접근하는 코드가 서버 사이드에서 실행되어야 하기 때문에 별도 서버 없이는 동작하지 않음
RAG 대신 md 파일을 택한 이유
LLM API에 넘기는 시스템 프롬프트에 참조 지식 문서를 함께 주입합니다. 테넌트별로 다른 문서를 로드하는 구조입니다.
function loadSystemPrompt(tenantId: string): string {
const parts: string[] = [];
// tenantId별 프롬프트 우선, 없으면 공통 prompt.txt
const prompt =
loadFile("prompt", `${tenantId}.txt`) ?? loadFile("prompt.txt");
if (prompt) parts.push(prompt);
// tenantId별 지식 문서 (com.md, nom.md 등)
const knowledge = loadFile("knowledge", `${tenantId}.md`);
if (knowledge) parts.push("[참조 지식 문서]\n" + knowledge);
return parts.join("\n\n");
}복잡한 벡터 검색이나 RAG 파이프라인을 구축하는 대신 md 파일을 직접 컨텍스트로 주입하는 방식을 택한 이유는 단순합니다. 시연 목적상 빠르게 수정하고 버전 관리할 수 있는 구조가 더 중요했기 때문입니다. 지식 문서는 Git으로 관리되므로 변경 이력도 남습니다.
운영 자동화: 반복 문의를 문서 보강으로 연결하기
주기적 보강 흐름 구성
운영하면서 생긴 가장 유용한 구조가 바로 지식 자동 보강 파이프라인입니다. 처음에는 GitHub Actions의 schedule 이벤트에 cron: '0 2 * * 1'을 설정해 매주 월요일 KST 11시에 자동 실행하도록 했습니다. 그런데 GitHub Actions cron은 서버 부하에 따라 수십 분씩 지연되거나 간헐적으로 누락되는 문제가 있습니다.
그래서 AWS EventBridge를 외부 스케줄러로 사용하는 방식으로 전환했습니다. EventBridge Rule이 정해진 시각에 GitHub API(workflow_dispatch)를 직접 호출하는 구조로, Lambda 없이 API Destination만으로 구성할 수 있습니다. 수동으로 즉시 실행하고 싶을 때는 Actions 탭에서 workflow_dispatch로 테넌트 ID와 분석 기간을 파라미터로 넘겨 실행할 수 있습니다.
S3 대화 로그 분석
↓
미해결 질문 + 반복 질문 패턴 추출
↓
현재 knowledge.md와 갭 탐지 (LLM)
↓
knowledge.md에 Q&A 섹션 자동 추가 (LLM)
↓
PR 생성 → 사람이 검토 후 머지
코드로는 세 단계로 나뉩니다.
1단계: 대화 분석
// 미해결로 판단하는 패턴 매칭
const UNRESOLVED_PATTERNS = [
/고객센터에\s*문의/,
/확인이\s*어렵/,
/알\s*수\s*없/,
/제공하지\s*않/,
];
// 스팸 필터
const SPAM_PATTERNS = [
/^[ㄱ-ㅎㅏ-ㅣ\s]{1,5}$/, // 자음/모음만
/^(.)\1{4,}$/, // ㅋㅋㅋㅋㅋ 등
];2단계: 갭 탐지
미해결 대화와 반복 질문 목록을 LLM에 보내 "현재 knowledge.md에 없는 주제"를 JSON으로 받아냅니다. 기존 질문과의 의미 중복도 LLM으로 필터링합니다.
3단계: 자동 보강
탐지된 갭에 대해 LLM이 Q&A 마크다운을 생성합니다. 이때 실제 GitHub 프론트 소스 코드를 함께 주입해 환각을 줄입니다.
# .github/workflows/improve-knowledge.yml
- name: Checkout front source
uses: actions/checkout@v4
with:
repository: {organization}/{front-repo} # 테넌트별 프론트 레포
path: front/com
- name: Run knowledge improvement
env:
CHAT_BOT_LLM_API_KEY: ${{ secrets.CHAT_BOT_LLM_API_KEY }}
TENANT_ID: com
DAYS_BACK: 7
run: npm -w packages/core run improve환각을 줄이기 위한 안전장치
생성된 문서를 그대로 반영하면 위험합니다. 세 가지 안전장치를 뒀습니다.
- 소스 코드 참조: 실제 프론트 소스를 컨텍스트로 주입해 존재하지 않는 기능을 안내하지 않도록 유도
- 프롬프트 제약: "코드에 없는 내용은 추측하지 마세요. 불명확하면 고객센터로 안내하세요"
- 사람이 검토: 최종적으로 PR을 생성해 개발자가 확인 후 머지
자동 생성이라도 사람의 검수 없이 반영되지 않도록 한 것이 핵심입니다.
운영 중 확인한 실제 개선 사례
운영하면서 가장 의미 있었던 점은 챗봇이 단순 응답 도구를 넘어서는 역할을 했다는 것입니다.
발견: 반복 문의 패턴에서 포착하다
주간 자동 분석이 돌면서 눈에 띄는 패턴이 하나 잡혔습니다. "이모티콘을 공유할 수 있나요?", "콘텐츠 링크를 친구에게 보내려면 어떻게 하나요?" 같은 질문이 서로 다른 사용자에게서 반복적으로 들어오고 있었습니다. 챗봇은 해당 기능이 없다고 안내하거나, 고객센터로 연결하는 응답을 돌려주고 있었습니다.
자동 분석이 이것을 repeatedQuestions로 집계해 올려줬고, 저는 그 목록을 보면서 "이건 단순히 문서가 부족한 게 아니라, 기능 자체에 대한 수요가 있는 것"이라는 판단을 할 수 있었습니다.
전달: 데이터로 팀에 공유하다
사용자가 몇 명이 물어봤는지, 어떤 표현으로 질문했는지를 구체적으로 정리해서 팀에 공유했습니다. "이런 요청이 있는 것 같다"는 느낌이 아니라, 실제 대화 로그와 빈도수가 근거로 있었기 때문에 논의가 빠르게 진행됐습니다.
결과: 기능이 실제로 만들어지다
공유하기 기능이 개발 일정에 포함됐고, 실제로 반영됐습니다. 배포 이후 사용자 행동 분석 도구인 Microsoft Clarity를 통해 해당 기능의 사용 현황을 살펴볼 수 있었고, 사용자들이 실제로 쓰고 있다는 것도 확인됐습니다.
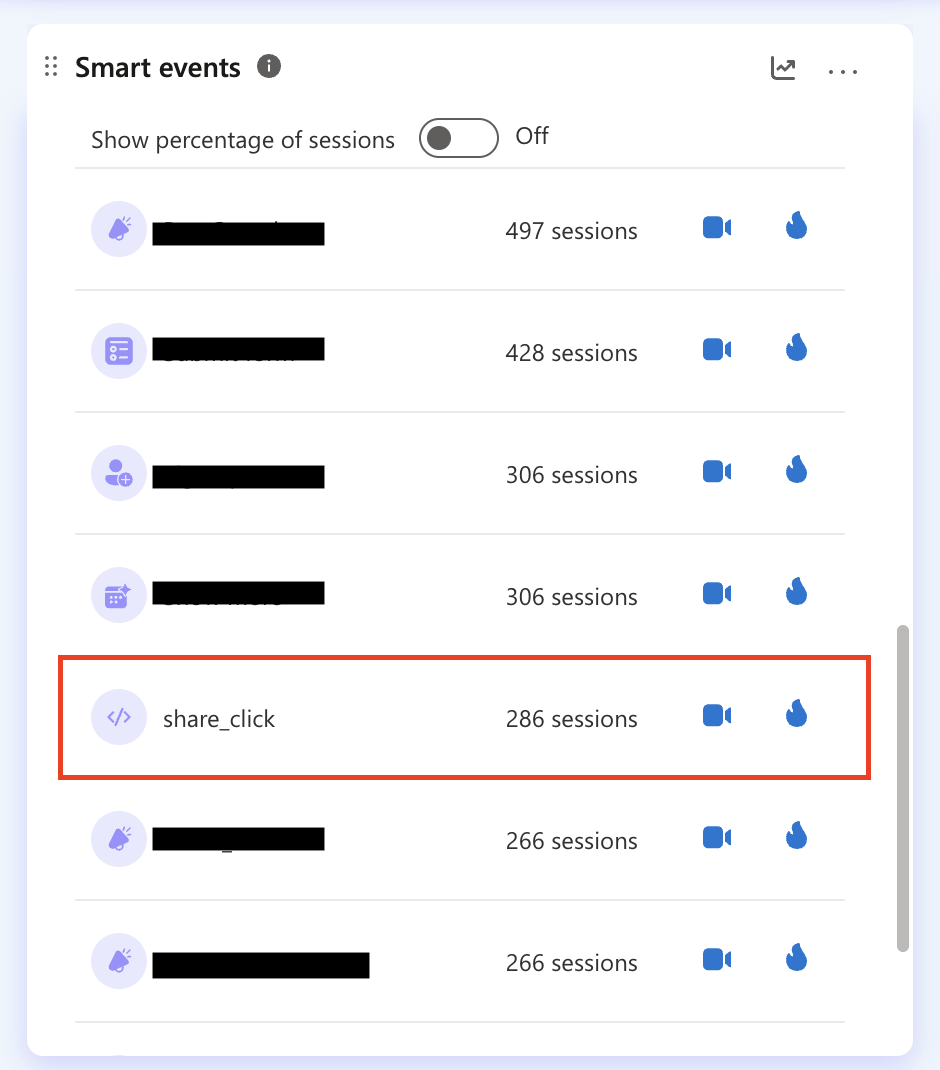
챗봇이 "잘 모르겠다"고 돌려보냈던 질문이 제품 개선으로 이어진 사례였습니다. 주목할 점은, 처음부터 의도한 구조가 아니었다는 것입니다. S3에 대화를 쌓고, 그걸 주기적으로 분석하는 파이프라인을 만든 목적은 knowledge base를 보강하기 위한 것이었습니다. 그런데 그 부산물로 제품 피드백 채널이 생긴 셈이었습니다.
챗봇이 단순 응답 도구를 넘어 제품 개선 포인트를 발견하는 채널로 작동했습니다.
운영 품질 지표
실제로 운영해보니 FAQ와 LLM의 분리가 숫자로도 드러났습니다. 응답 속도부터 정리하면 이렇습니다.
| 구분 | 응답 속도 | 정확도 |
|---|---|---|
| FAQ | 50~100ms | 100% (사전 정의 Q&A) |
| LLM | 첫 토큰 0.8~1.5초, 전체 2~4초 | knowledge base 범위 내 질문 기준 90% 이상 |
FAQ는 정적 JSON 매칭이라 틀릴 일이 없고, 속도도 체감할 수 없을 정도로 빠릅니다. LLM 쪽은 프롬프트에서 knowledge base 범위 밖 질문을 거부하도록 설정해 두었기 때문에, 범위 내 질문에 대한 정확도는 상당히 높았습니다. 다만 범위 경계에 걸치는 질문에서 간혹 부정확한 답변이 나오는 경우가 있었습니다.
흥미로웠던 건 전체 질문의 60~70%가 FAQ만으로 해결됐다는 점입니다. 덕분에 LLM API 호출량이 예상보다 훨씬 적었고, 비용 절감 효과도 컸습니다. knowledge base를 보강하기 전에는 주간 미해결 질문이 10~15% 정도였는데, 자동 보강 파이프라인을 돌린 뒤에는 5~8%까지 내려갔습니다. "도움이 됐어요" 피드백도 4명 중 3명 이상이 긍정으로 눌러주고 있어서, 시연용으로 시작한 것치고는 꽤 쓸 만한 수치였습니다.
해보니 어땠는가
구현 속도는 분명히 빨랐습니다. 혼자서 백엔드·프론트엔드를 아우르는 시스템을 단기간에 만들 수 있었습니다. 하지만 이면도 있었습니다.
잘 된 점:-
구조 선택을 사람이 하고 구현을 AI에 맡기는 방식은 효과적이었습니다.
-
패키지 분리(
core/widget)와 Web Standard 핸들러 설계 덕분에 여러 프로젝트에 붙이는 게 예상보다 수월했습니다. -
자동 지식 보강 파이프라인은 지식 문서(
knowledge.md)를 수동으로 관리하는 공수를 크게 줄여줬습니다. -
비용이 크게 줄었습니다. 기존 외부 챗봇 서비스는 7일 만에 약 120달러가 청구됐지만, LLM API로 전환한 뒤에는 약 1,700건의 대화가 발생했음에도 비용은 $1~2 수준에 그쳤습니다.
사용한 LLM API 기준 입력 $0.10/1M · 출력 $0.40/1M. 대화당 입력 ~2,000 토큰, 출력 ~300 토큰으로 추정하면 1,700건 합산 약 $0.54.
- 디버깅이 힘들었습니다. 직접 짠 코드가 아니다 보니 에러가 발생했을 때 원인을 파악하는 데 시간이 더 걸렸습니다.
- 도메인 지식이 필요했습니다. AI가 제안한 구조가 실제 운영에 적합한지 판단하려면 결국 사람의 이해가 필요했습니다. 특히 AWS 권한 설정이나 Docker 배포 설정 같은 인프라 영역은 AI 출력만으로는 검증하기 어려웠습니다.
- 서버리스 환경 지원: Vercel Edge Functions, AWS Lambda 등에서도 동작할 수 있도록 별도 서버 없이 배포 가능한 구조로 개선
- S3 → DB 마이그레이션 + RAG 도입: 집계·검색이 용이한 DB 구조로 전환하고, 유사도 기반 검색을 도입해 지식 문서 규모가 커져도 정확도를 유지할 수 있도록 개선
- 외부 API 연동: 단순 상담 응답을 넘어 실제 업무를 수행할 수 있도록 API 연동 검토 (부작용 방지를 위한 권한·확인 절차 설계가 선행 필요)
마무리
바이브 코딩은 빠른 프로토타이핑에는 강력했습니다. 하지만 운영 가능한 구조를 만들기 위해서는 사람의 설계와 검증이 계속 필요했습니다.
예상보다 의미 있었던 점은, 챗봇이 단순 응답 도구를 넘어 실제 제품 개선 포인트를 발견하는 창구로도 작동했다는 것입니다. 운영 데이터가 제품 개선으로 이어지는 구조는 다음 시스템 설계에도 적용할 수 있는 패턴이었습니다.
Related Posts

이벤트 페이지를 AI로 만들며 무엇을 모델에 맡길지 정하기
빌더로 개발자 의존은 없앴지만 디자이너를 기다리는 하루는 남았습니다. 배경과 문구를 AI로 생성하며, 무엇을 모델에 맡기고 무엇을 코드로 남길지 가른 과정입니다.

Vanilla JS 댓글 모듈 자체 개발기
프레임워크 독립적인 Vanilla JS 댓글 모듈을 설계·개발하고 기존에 서비스 중이던 Nuxt 3 프로젝트에 통합한 과정을 다룹니다.

결제 비밀번호 입력을 위한 숫자패드 컴포넌트 개발 과정
React와 Zustand를 사용하여 결제, 등록, 변경 등 다양한 시나리오에 대응하고, 보안까지 강화한 범용 Numpad 컴포넌트의 설계와 구현 과정을 자세히 살펴봅니다.