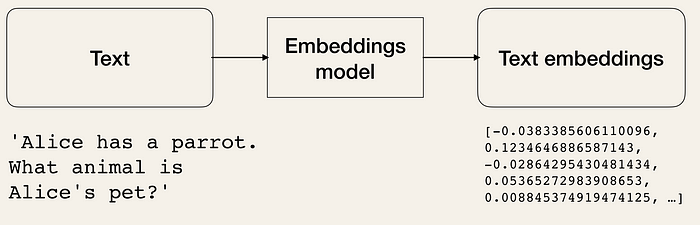
Text Embedding이란?
Text Embedding은 단어, 문장, 문서와 같은 텍스트 데이터를 실수 벡터로 표현하는 기술입니다. 이 과정을 통해 텍스트의 의미적·문맥적 정보를 기하학적 공간에 매핑하여 컴퓨터가 이해하고 처리할 수 있게 됩니다. 이러한 실수 벡터는 단어의 유사성을 반영하기 때문에 유사한 단어끼리 비슷한 형태를 가지게 됩니다.
챗봇, 기계 번역, 추천 시스템, 문서 요약 등 다양한 분야에 응용할 수 있지만, 이 글에서는 간단한 예제로 벡터를 비교하여 입력한 키워드와 유사한 검색 결과를 반환하는 부분까지 다룹니다.
개발 환경
- Front-end:
Vue,Vuetify,TypeScript로 구현했습니다. 프론트엔드 쪽은 다른 프레임워크를 사용하셔도 무방합니다. - Back-end: AI 관련 라이브러리가 풍부하고 문법이 비교적 쉬운
Python을 선택했습니다. 또한AWS Lambda+AWS API Gateway로 serverless 환경을 구성했습니다. - Database:
MongoDB Atlas를 사용했습니다. 무료로 시작할 수 있고, 서울 리전 데이터센터를 통해 접근 속도가 비교적 빠르며, 무엇보다 벡터 연산을 지원하기 때문입니다. - Model: serverless 환경을 고려하여 별도 설치가 필요 없고 비용 부담이 상대적으로 적은 OpenAI Embeddings API를 사용했습니다.
구현 방법
Text Embedding을 활용한 검색 기능의 플로우차트는 대략 다음과 같습니다.
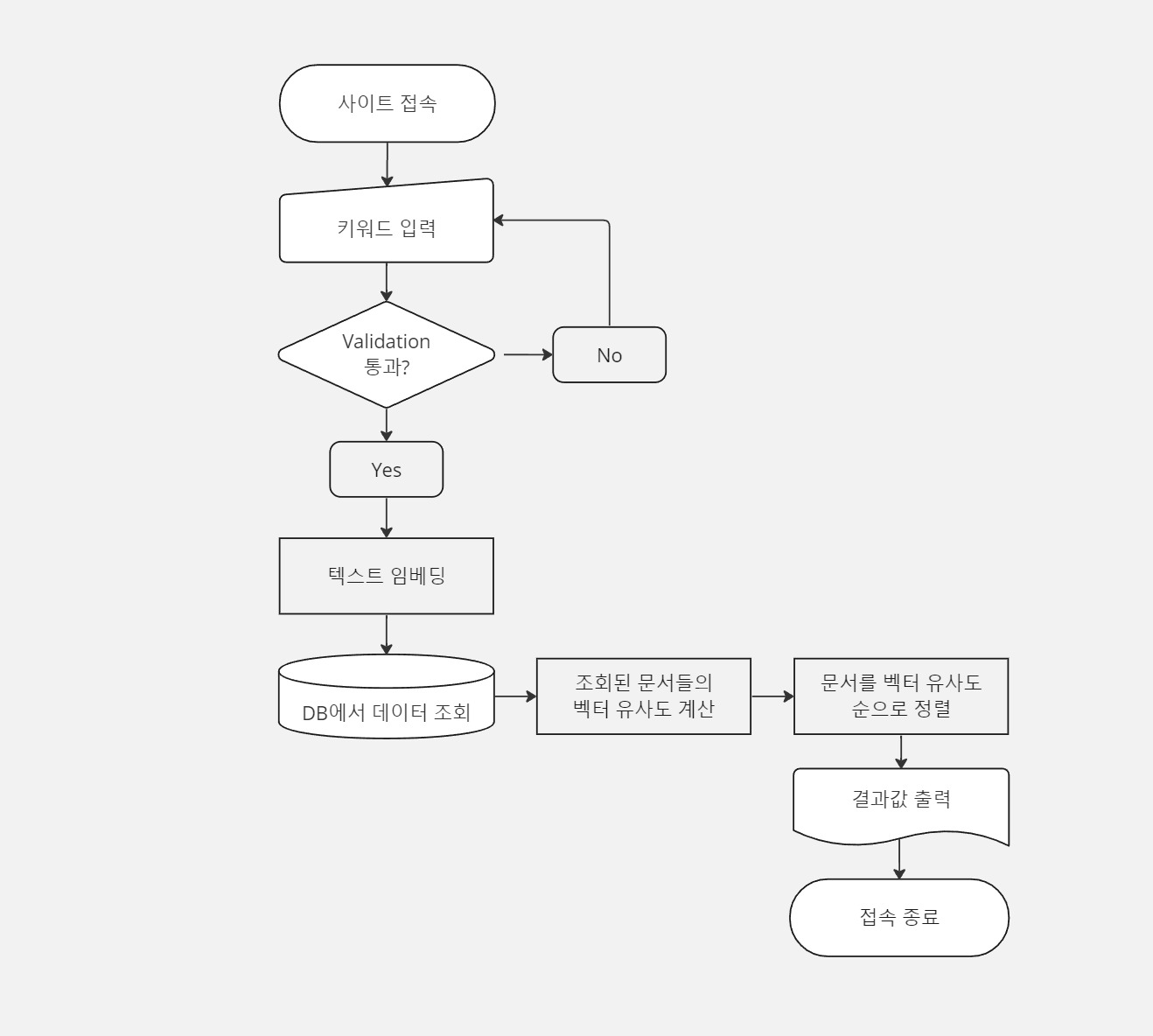
- 사용자 쿼리 입력: 사용자가 검색어를 입력합니다.
- 텍스트 임베딩: 입력된 검색어를 Text Embedding 모델을 사용해 벡터로 변환합니다.
- 데이터베이스 조회: 저장된 문서들의 임베딩 벡터를 데이터베이스에서 조회합니다.
- 유사도 계산: 벡터 연산으로 검색어 벡터와 문서 벡터들 간 유사도를 계산합니다.
- 순서 정렬: 유사도에 따라 문서를 정렬해 가장 관련성 높은 문서를 사용자에게 반환합니다.
1. 사용자 쿼리 입력
// vue.js
<v-form @submit.prevent="searchFruit">
<v-text-field
class="mt-4"
v-model="keyword"
label="검색할 과일을 입력해주세요."
/>
<v-btn class="mt-2" type="submit" block>Submit</v-btn>
</v-form>
const keyword = ref<string>("");
async function searchFruit(){
const response = await fetch(`${apiGatewayUrl}?s=${keyword.value}`);
const result = await response.json();
fruitList.value = result.data;
console.log("fruit List", result);
}client-side에서 사용자가 입력한 키워드는 searchFruit() 내부의 fetch 함수를 통해 미리 지정된 API Gateway URL로 전달됩니다. 해당 URL이 호출되면 AWS Lambda에서 entry point로 지정한 lambda_handler 함수가 실행됩니다. 아래는 Python으로 작성한 백엔드 함수 코드입니다.
# in AWS Lambda
import json
import requests
from pymongo import MongoClient
mongo_uri = "<MONGO_URI>"
open_api_key = "<OPEN_API_KEY>"
client = MongoClient(mongo_uri)
def lambda_handler(event, context): # 특정 API GateWay URL이 호출되면 실행
db = client['shop']
collection = db['product_items']
keyword = event['search-text']
embedding = searchKeyword(keyword) # 키워드를 openAI의 API를 통해 벡터로 변환
result = list(searchOneData(embedding, collection)) # DB에서 벡터와 유사도가 높은 결과값을 출력
return {
"statusCode": 200,
"keyword": keyword,
"data": result
}lambda_handler 함수가 실행되면 MongoDB 연동을 준비하고, 성공적으로 연결되면 searchKeyword() 함수를 호출합니다. 이때 event 객체에 담긴 검색어도 함께 전달합니다.
2. 텍스트 임베딩
def searchKeyword(keyword):
response = requests.post("https://api.openai.com/v1/embeddings", headers={
"Content-Type": "application/json",
"Authorization": f"Bearer {open_api_key}",
},
json={
"input": keyword,
"model": "text-embedding-3-large",
"encoding_format": "float"
})
embedding = json.loads(response.text)['data'][0]['embedding']
return embeddingkeyword를 OpenAI Embeddings API의 body에 넣어 호출하면 벡터로 변환된 값을 반환합니다. 키워드로부터 변환된 벡터는 부동소수점 배열 형태를 가집니다.
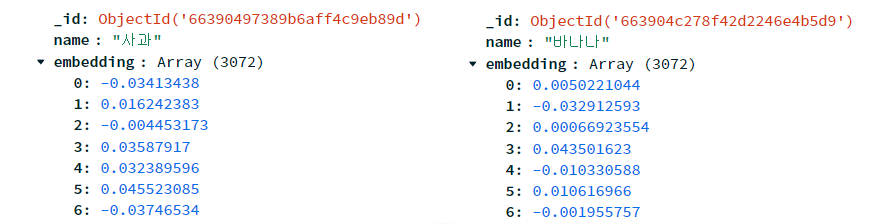
3. 데이터베이스 조회 및 결과 반환
남은 단계에서는 데이터베이스를 조회하고, 각 아이템과 입력 벡터의 유사도를 비교한 뒤, 유사도가 높은 순서대로 반환하는 과정이 필요합니다. 다행히도 MongoDB는 벡터 연산을 지원하므로 앞서 말한 과정들을 한 번에 처리할 수 있습니다.
def searchOneData(embedding, collection):
return collection.aggregate([ # 여러 문서를 처리하고 계산된 결과를 반환하는 함수
{
"$vectorSearch": {
"index": "embedding",
"path": "embedding",
"queryVector": embedding,
"numCandidates": 100, # 후보 문서의 수
"limit": 5 # 최대 5개
}
},
{
"$project": {
"_id": 0, # 테이블에서 name, seq, score만 가져와서 문서를 반환함
"name": 1,
"seq": 1,
"score": {
"$meta": "vectorSearchScore" # 이전 단계에서 계산된 벡터 검색 점수를 현재 문서의 score 필드로 반환
}
}
},
{
"$match": {
"score": { "$gte": 0.5 } # 유사도 점수 0.5 이상인 문서 필터링
}
}
])aggregate() 함수는 여러 문서를 한 번에 처리하고 계산된 결과를 반환하는 함수입니다. 파이프라인을 통해 결과를 계산하고 걸러내는데, 각 단계는 다음과 같습니다.
1. $vectorSearch 단계
벡터 연산이 이루어지는 단계입니다.
- index: 사용할 벡터 인덱스의 이름을 지정합니다. 여기서는 "embedding" 인덱스를 사용했습니다.
- path: 문서 내에서 벡터 데이터가 위치하는 필드의 경로입니다. 여기서도 "embedding" 필드를 사용합니다.
- queryVector: 검색할 벡터입니다.
embedding변수에 저장된 벡터 값을 사용해 쿼리를 수행합니다. - numCandidates: 검색 과정에서 고려할 최대 후보 문서 수입니다. 여기서는 100개 문서를 후보로 설정했습니다.
- limit: 최종 결과로 반환할 문서 수를 제한합니다. 여기서는 상위 5개 문서만 반환합니다.
2. $project 단계
각 문서의 특정 필드만 선택하여 반환하는 단계입니다.
- _id: 문서의 ID 필드를 제외하고,
name및seq필드를 포함시킵니다(1은 포함, 0은 제외를 의미합니다). - score: 검색 결과의 점수를 포함합니다.
"$meta": "vectorSearchScore"를 사용하면 이전 단계에서 계산된 벡터 검색 점수를 현재 문서의score필드로 포함해 반환하도록 설정할 수 있습니다.
3. $match 단계
특정 조건을 만족하는 문서만 필터링하는 단계입니다. 여기서는 문서의 유사도 점수가 0.5 이상인 것만 포함하도록 필터링 조건을 걸었습니다. 따라서 위 코드는 "embedding" 벡터 인덱스를 사용해 주어진 벡터와 유사한 문서를 검색하고, 그중 점수가 0.5 이상인 상위 5개 문서의 이름, 순서, 점수만을 반환한다는 의미입니다.
유사도 임계값과 검색 정확도
위 코드에서 유사도 점수를 0.5 이상으로 필터링한 이유를 설명하겠습니다. 임계값을 0.3부터 0.7까지 올려가며 테스트해봤는데, 낮은 값(0.3~0.4)에서는 재현율이 90% 이상으로 높지만 관련 없는 결과가 많이 섞여 정밀도가 45~70% 수준에 머물렀고, 반대로 높은 값(0.6~0.7)에서는 정밀도가 90% 이상이지만 관련 있는 결과까지 절반 가까이 누락되었습니다. 0.5가 F1 Score 0.78로 가장 높은 균형점이었고, 정밀도 80~85%에 재현율 75~80%를 확보할 수 있었습니다. 사용자 입장에서는 관련 없는 결과가 섞이는 것이 관련 있는 결과가 빠지는 것보다 더 불편하게 느껴지기 때문에, 정밀도가 80% 이상 확보되는 0.5가 적절한 선택이었습니다.
비용 분석
text-embedding-3-large 모델 기준으로 실제 비용이 어느 정도인지 정리해봤습니다.
- 임베딩 API 단가: 1K 토큰당 $0.00013 (text-embedding-3-large 기준)
- 쿼리당 평균 토큰: 한국어 짧은 검색어 기준 10~30 토큰 정도로, 쿼리 한 건당 비용은 $0.000003 수준
- 월 1만 쿼리 기준: 약 $0.03으로 사실상 무시할 수 있는 금액
- MongoDB Atlas: 무료 티어(512MB 스토리지)에서도 벡터 검색을 지원하므로 DB 비용도 $0
소규모 프로젝트에서는 비용 걱정 없이 시작할 수 있습니다. 다만 문서 수가 수만 건 이상으로 늘어날 경우 초기 임베딩 생성 비용과 인덱스 크기를 고려해서, 차원 수 축소(dimensions 파라미터)나 배치 처리를 검토할 필요가 있습니다.
실행 결과
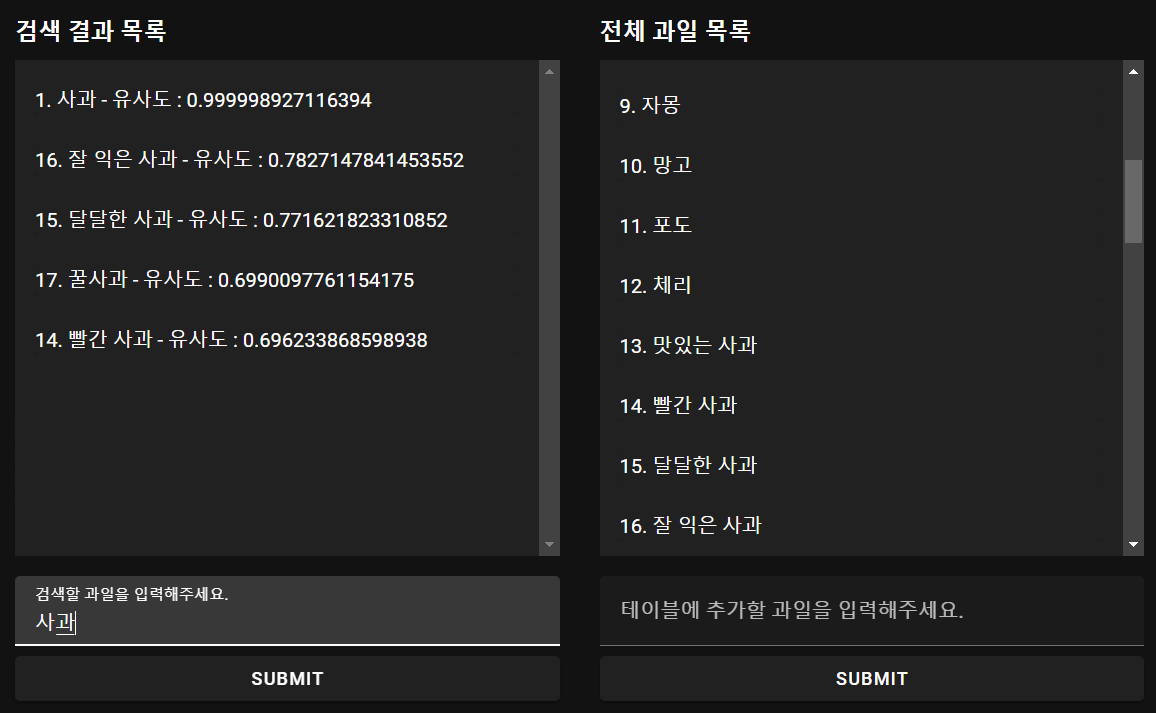
사진처럼 "사과"로 검색했을 때 유사도가 높은 순으로 결과가 정렬되는 것을 알 수 있습니다.
샘플 코드
참고 자료
Related Posts

이벤트 페이지를 AI로 만들며 무엇을 모델에 맡길지 정하기
빌더로 개발자 의존은 없앴지만 디자이너를 기다리는 하루는 남았습니다. 배경과 문구를 AI로 생성하며, 무엇을 모델에 맡기고 무엇을 코드로 남길지 가른 과정입니다.

구조화와 검증이 더 중요했다 - 바이브 코딩으로 챗봇을 만들며 배운 것들
기존 챗봇이 사용 불가해진 상황에서 바이브 코딩으로 챗봇을 직접 만든 경험을 정리합니다. LLM API, S3 로깅, GitHub Actions 자동 지식 보강까지 구현한 과정과 설계 판단을 기록합니다.

VS Code에서 Pylint import error(E0401) 해결하기
VS Code에서 모듈이 설치되어 있는데도 `Unable to import` 오류가 발생할 때, Python Interpreter 설정을 점검하여 해결한 과정을 정리합니다.